
As study materials scatter across formats, the important thing becomes less about getting more summaries and more about building a personal knowledge system where sources and questions stay connected.
When there is too much material to study, organizing it quickly becomes the bottleneck.
There are lecture videos, slides, transcripts, ChatGPT conversations from my own questions, papers I looked up in the middle, and blog posts I clipped along the way. In the past, I would have read them one by one, underlined things, and manually organized notes in Notion or Obsidian. But now another approach is starting to become possible.
You put in the raw data and let an LLM build a wiki.
The experiment I tried was roughly this. While studying hardware lectures from KAIST DRCD Lab, I collected lecture materials, transcripts, my ChatGPT study conversations, related papers, and references into one folder. Then I ran those raw materials through an LLM Wiki workflow that connected Codex, Claude, and Obsidian.
The result was not just a summary.
Each concept became a wiki page. Links appeared between concepts. When I asked about something I did not understand, the answer could become a new note. A study path following the lecture sequence appeared, and concepts I had been confused about, such as motor structure, BLDC, and PMSM, were separated into their own explanations.
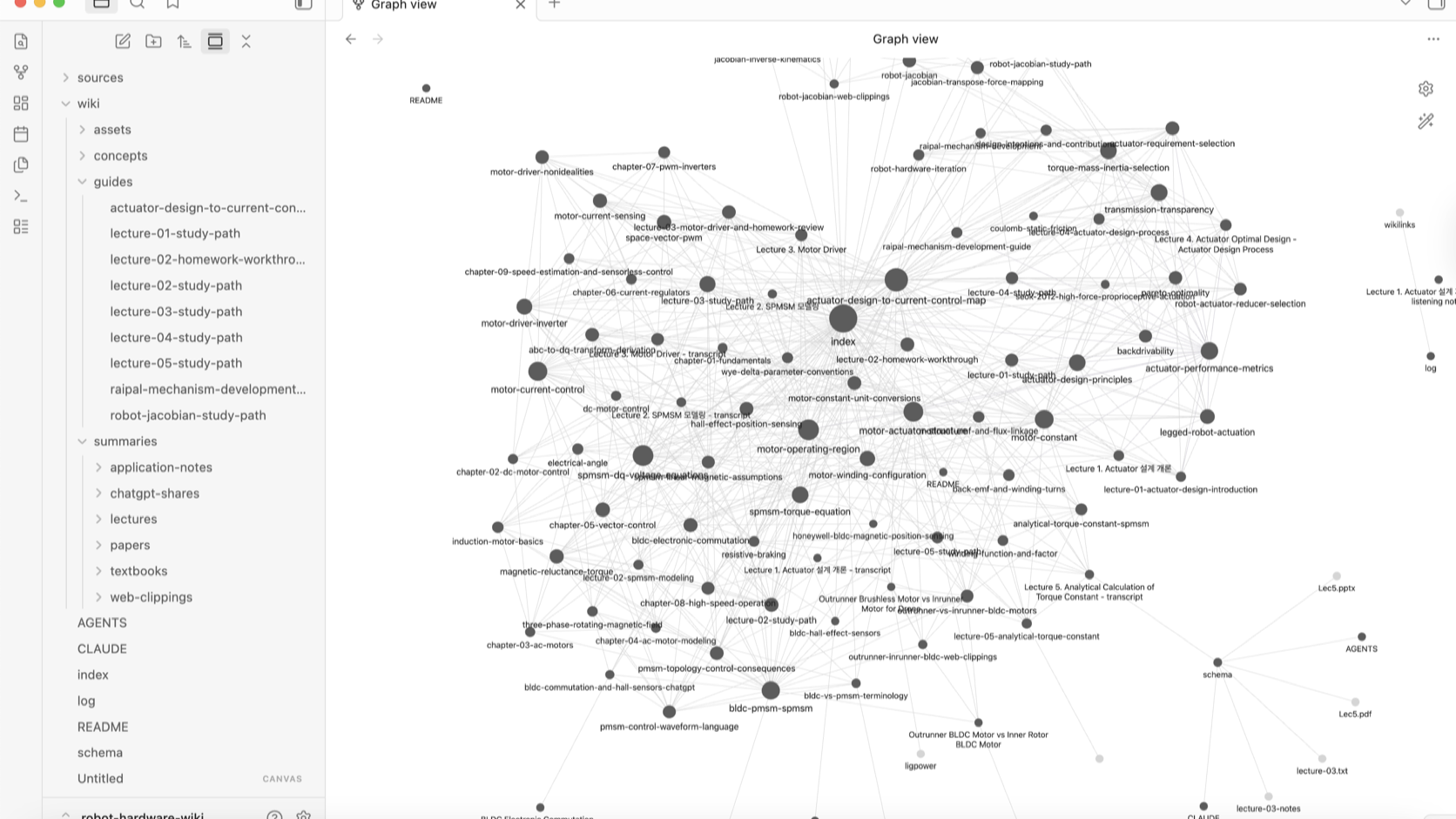
The LLM Wiki does not leave lectures, papers, and questions as isolated notes. It turns them into a connected knowledge graph.
This did not feel like "AI studying for me."
More precisely, it felt like the interface for studying was changing.
Maybe the learning paradigm itself is starting to shift. The old default was to follow a curriculum someone else had organized, then stack my own notes on top of it. Now the traces I leave behind, including questions, conversations, transcripts, and references, can be gathered first, and an agent can keep restructuring them into a learning path that fits me. Studying becomes less like consuming a fixed textbook and more like editing a personalized knowledge system from the raw material I created.
An LLM Wiki Starts With Raw Data, Not Polished Notes
When we say we are studying, we usually try to organize the material first.
We listen to a lecture, write down the important parts, look up unfamiliar concepts, and make notes we can revisit later. That process is useful, but it takes a lot of time. It is especially hard when learning a field for the first time, because you do not yet know what matters. You do not know which terms are central, which diagram you need to understand, or which equation will keep reappearing later.
The LLM Wiki approach changes the order.
First, you put in raw data. Lecture slides, transcripts, PDFs, papers, web pages, screenshots, and even the conversations where you asked questions all become material. Then the LLM uses those materials to create concept pages. It extracts recurring concepts, connects them, attaches the original sources, and sometimes breaks them down into smaller sub-concepts.
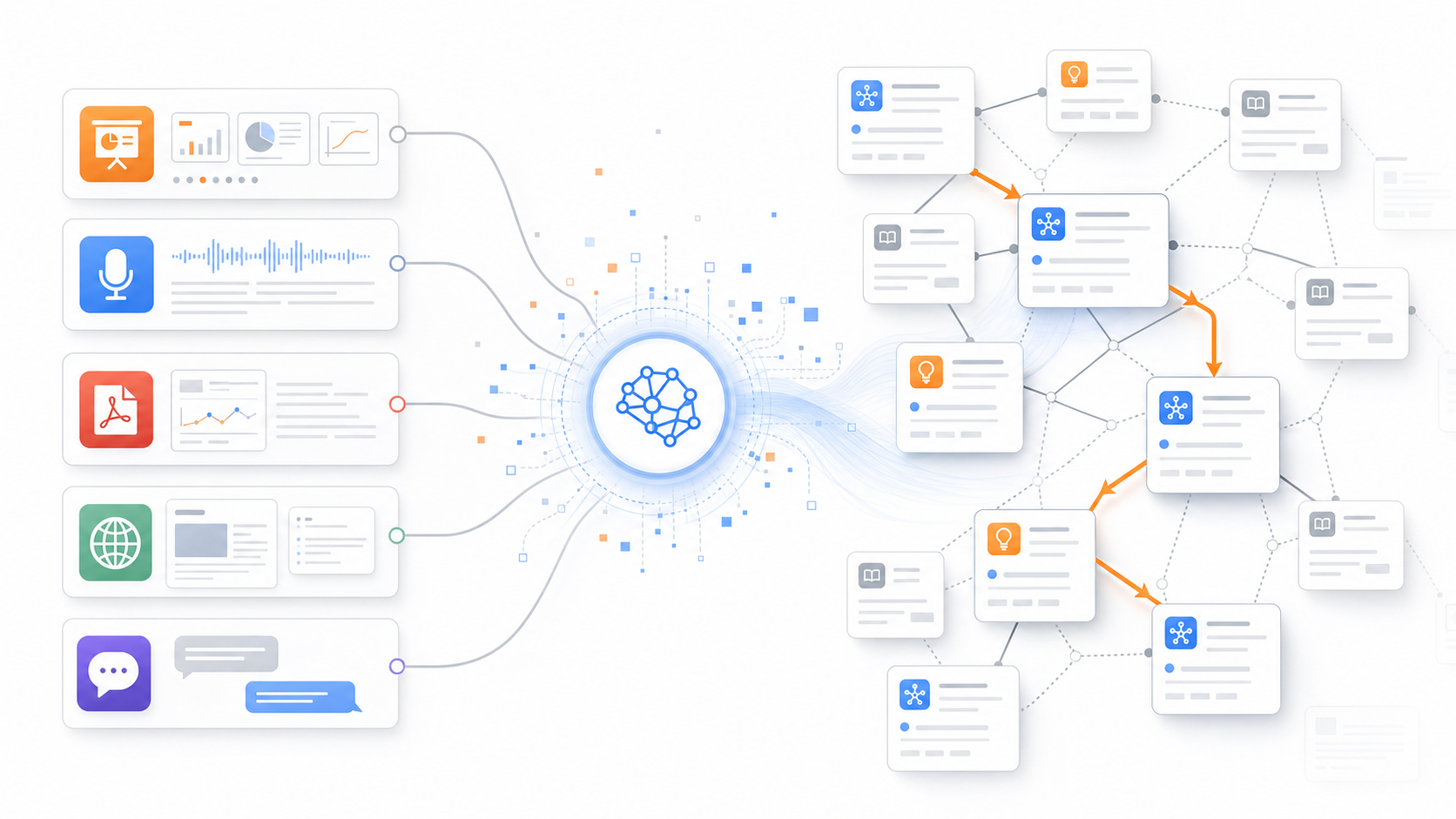
When slides, transcripts, PDFs, web clippings, and questions enter the system, the LLM reorganizes them into concept pages and study paths.
The important part is not making a pretty summary.
A good wiki should be something you can question again. If I am reading a page and ask, "Why does this equation take this form?", the LLM can answer using the lecture context already ingested into the wiki. If the answer is useful, it can go back into the wiki. Then the wiki is not a fixed document. It is a structure that grows through questions.
This is different from a normal note app. A note app grows only as much as I write. An LLM Wiki can use the raw data I added and the questions I asked to suggest connections I have not yet organized myself.
A Beginner's Questions Become Source Material
One thing I intentionally included was my ChatGPT conversations.
When I was listening to the lectures, I did not have enough background in hardware or motors. The lecturer naturally skipped over concepts that they assumed the audience already knew, but I often got stuck before that point. So while listening, I kept asking ChatGPT what something meant, what a diagram was showing, why an equation appeared, and how one term differed from another.
At first, I thought of those conversations as just a personal aid.
But once I put them into the LLM Wiki, the conversations themselves became valuable study material. They contained the exact places where a beginner gets stuck. If you only add the lecture slides, you preserve the expert's explanation structure. But if you also add the learner's questions, you preserve the path that someone actually had to walk to understand the material.
That matters when building educational material.
Lecturers create material from the perspective of what they already know. That makes it easy to miss where beginners slip. When learner questions are included, the wiki is not merely summarizing the lecture. It becomes better at capturing the order in which a new learner may need to understand things.
This was one of the parts I found genuinely useful. The LLM created concept pages from the lecture material, then created more basic pages from the places where I had gotten stuck. Front-end concepts such as what a motor is, what an actuator is, and how a rotor and stator differ appeared naturally.
The wiki became a slightly more personalized textbook than the original lecture.
A Study Path Was More Useful Than a Summary
The first generated wiki was centered on concepts.
The individual concepts were organized well, but that created another problem for me as a learner. I did not know what order to read them in. A wiki is a network, so links open in every direction. For a beginner, that freedom can be more burden than benefit.
So I asked the LLM to create a study path.
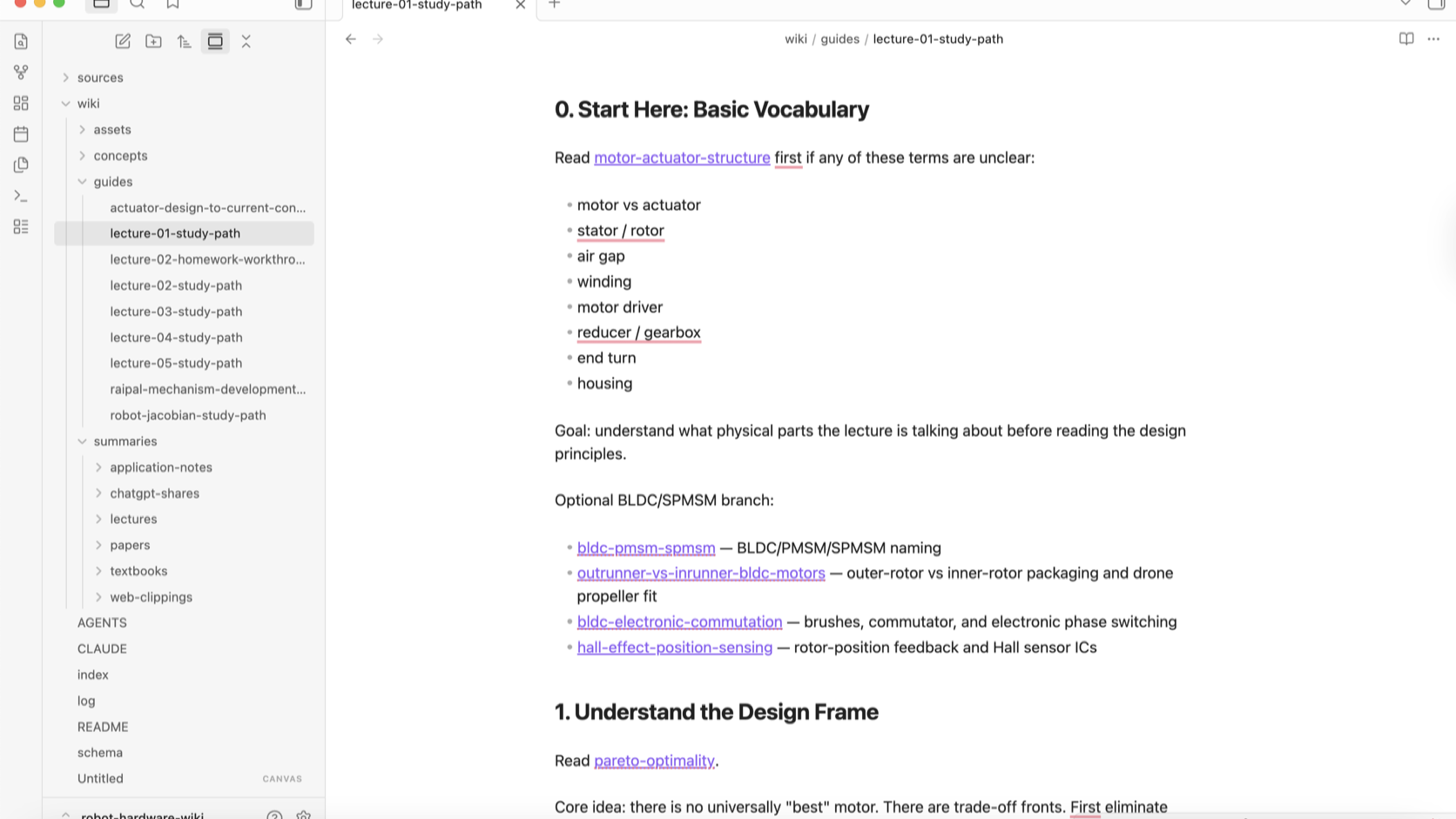
A connected graph is not enough. A beginner needs a path that says which concepts to read first.
For example, to understand the first lecture, it organized which concepts should be read first, what page should come next, which optional branches existed, and what order would make sense for review. At that point, the wiki stopped feeling like just a reference and started feeling like a curriculum.
That difference was large.
A summary is useful for someone who already knows the rough shape of the topic. But for someone learning for the first time, the more urgent question is, "What should I look at next?" A study path answers that question. Even after finishing the lecture, I could go back into Obsidian, follow the path, read related pages, and ask questions again when something was unclear.
It did not feel like AI replacing study. It felt more like AI laying down a road that made studying possible.
Images And Diagrams Are The Next Bottleneck
One thing I felt strongly during this experiment was the importance of images.
New hardware concepts do not always enter the head through words. For things like motor structure, coordinate transforms, and actuator internals, a single good diagram can do more than several paragraphs of explanation. But from the perspective of someone making lecture material, finding or creating those diagrams takes a lot of time. You know what image you want in your head, but it is hard to find the exact material, so you either draw it yourself or use something close enough.
Recent image models make me think this part could change a lot.

In technical learning, one diagram can replace several paragraphs. The next bottleneck is the ability to generate the right diagram for the concept on demand.
For example, if you put in one complicated diagram and ask, "Redraw this from multiple angles with labels so a beginner can understand each part," you can get surprisingly useful explanatory images. They are not yet reliable enough to trust blindly, but for personal study they are already powerful.
If this becomes part of the LLM Wiki, the way we study can change further.
The system would extract concepts from raw data, create explanations, build a study path, and then generate new images for the parts where understanding breaks down. Lecture material would no longer be a fixed PDF. It would become closer to an interactive textbook that keeps restructuring itself around the learner's current state.
This matters especially for technical learning, where equations, diagrams, concepts, and examples need to stay connected.
The Feeling Of Studying By Hand Still Matters
That does not mean this approach is perfect.
The biggest thing I missed was the feeling of organizing things with my own hands. I am still used to understanding by writing things down, deriving equations, and redrawing diagrams myself. Reading a well-organized page produced by an LLM is convenient, but that convenience can also let understanding pass too shallowly.
This is especially true for mathematical subjects.
An LLM can explain the derivation. But it is difficult to replace the process of following each line myself, making mistakes, recalculating, and physically experiencing where I get stuck. So my conclusion is not, "Just read the LLM Wiki."
The roles are different.
The LLM Wiki builds the map. It connects concepts, receives questions, and finds relevant material again. But deep understanding still appears when I move my own hands. A good workflow should mix both. First, use the wiki to create the map. Then, at important points, calculate or organize things manually. Then put those results back into the wiki so the material improves.

Even if AI builds the map, deeper understanding comes from asking questions, working things through by hand, and feeding the result back into the wiki.
Study Tools Can Become Agent Interfaces
This experiment also made me think that study tools may increasingly become agent interfaces.
Right now, the material is in Obsidian, Codex or Claude reads it, I ask questions, and files are updated when needed. If this structure becomes more natural, studying will feel less like working inside a document app and more like continuously adjusting a knowledge base with an agent.
In the past, I wrote notes.
Now I collect raw material, ask questions, the agent builds structure, I review that structure, and then I ask better questions. The center of studying moves a little from "organizing" toward "conversation and editing."
That change may look small, but it is not.
So far, we have often used AI as a summarization tool. But what studying really needs is more complex than a summary. I need to find what I do not know, create links between concepts, preserve a structure I can revisit, and keep that structure updated over time.
An LLM Wiki is one experiment in that direction. It treats AI not as a tool that answers one question once, but as a system that stays inside my learning environment. Then what we need is not just a better prompt. We need better source management, better memory, and better feedback loops.
The conclusion I took from this experiment is simple.
Studying with AI is not about receiving a summary. It is closer to building a personal knowledge system that continually reorganizes the materials I gathered, the questions I asked, what I understood, and what I still do not understand. The LLM Wiki felt like a genuinely interesting starting point for that system.